

Profesor linguistik dari Massachusetts Institute of Technology (MIT), Noam Chomsky, bilang satu-satunya kontribusi [ChatGPT buatan OpenAI] pada sistem pendidikan adalah mempersulit mendeteksi plagiarisme.
“[…] tak berkontribusi apa-apa terhadap pendidikan, malah merusaknya. ChatGPT pada dasarnya adalah plagiarisme berteknologi tinggi,” ujar profesor berusia 94 itu dalam sebuah wawancara.
Plagiarisme secara tradisional diterjemahkan sebagai “penjiplakan yang melanggar hak cipta”, demikian menurut KBBI daring. Deskripsi tersebut terbilang sempit bila dibandingkan dengan versi lain, semisal dari Universitas Oxford yang menyatakan:
“Plagiarisme menyajikan karya atau ide orang lain sebagai milik Anda, dengan atau tanpa persetujuan mereka, dengan memasukkannya ke dalam karya Anda tanpa pengakuan penuh.”
Tuan Chomsky sadar mesin ini “belajar” dari sumber pengetahuan secara masif, tapi ia menampik teknologi tersebut menawarkan buah pikiran baru.
Chomsky bicara dalam konteks karya ilmiah di dunia akademik yang selama ini menghadapi isu plagiarisme. Gagasan atau karya disebut otentik bila gagasan tersebut belum pernah dilontarkan pihak lain—setidaknya secara resmi dalam forum akademis.
Untuk memastikan itu para profesor akan mengujinya. Di sinilah ChatGPT ia klaim mempersulit kerja-kerja akademikus karena plagiarisme ala robot generatif termutakhir. Di satu sisi plagiarisme semakin mudah dipraktikkan, di sisi lain semakin sulit dibuktikan.
Maraknya penggunaan ChatGPT di mata Chomsky adalah bukti kemalasan dalam belajar. Ini dampak dari pembelajaran yang membosankan, tak menarik minat mahasiswa. Bagi mahasiswa yang punya minat mempelajari sesuatu, ia akan rela berupaya semaksimal mungkin—sekeras mungkin.
Menumbuhkan minat untuk belajar adalah sisi lain yang perlu jadi perhatian—alih-alih sibuk mencegah pemanfaatan AI. “Ibarat keberadaan ponsel pintar di dalam kelas,” kata dia mencoba membuat analogi.
Saat murid dibiarkan menggunakan ponsel di dalam kelas, ia lebih tertarik ngobrol dengan temannya via aplikasi daripada mendengarkan ceramah boring gurunya. Melarang ponsel di dalam kelas mungkin solusi, tetapi tak kalah penting adalah meningkatkan daya tarik pembelajaran.
Ini bukan kritik pertama Tuan Chomsky terhadap kecerdasan buatan alias AI. Ia juga pernah bilang bahwa penggunaan teknik statistik yang intens dalam data besar tidak menghasilkan wawasan yang lebih baik dari yang bisa ditawarkan pemikirain sains.
Bagi Chomsky, “AI baru”—berfokus pada penggunaan teknik pembelajaran statistik untuk mempelajari dan memprediksi data dengan lebih baik—kemungkinan tidak bisa menghasilkan prinsip umum tentang sifat makhluk cerdas atau tentang kognisi.
“Kita tidak akan banyak mengajari komputer tentang apa sebenarnya arti frasa ‘fisikawan Sir Isaac Newton’, bahkan jika mesin telusur mampu mengembalikan hasil pencarian yang masuk akal kepada pengguna yang mengetikkan frasa tersebut,” katanya.
Kritik pada lebih dari satu dekade silam itu sempat ditanggapi direktur penelitian Google yang juga seorang peneliti AI, Peter Norvig. Menurutnya penggunaan model statistik dalam metode AI tidak jauh berbeda dari apa yang berlaku di ranah keilmuan lain.
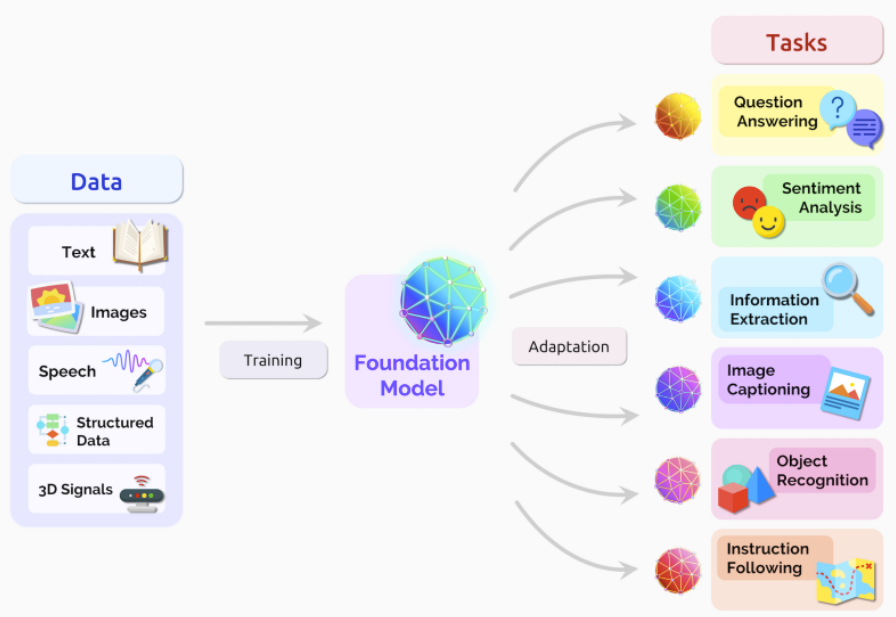
Generative AI adalah istilah umum untuk tren teknologi kecerdasan buatan (artificial intelligence) dengan algoritme pembelajaran tanpa pengawasan (unsupervised) untuk memproduksi gambar digital, video, audio, teks, ataupun kode baru.
Mesin pencari Bing yang diotaki ChatGPT generasi termutakhir buatan OpenAI hanya salah satu contoh, khususnya di bidang bahasa alami (natural language). Bard besutan Google—konon pesaingnya—juga termasuk dalam kategori kecerdasan buatan generatif ini.
Ia dibangun dengan teknologi Large Language Model/LLM (model bahasa maksi), yaitu model pembelajaran mendalam (deep learning) untuk pemrosesan bahasa alami (NLP – Natural Language Processing) dan pembuatan bahasa alami (NLG – Natural Language Generation).
Tugas model ini memprediksi teks yang mungkin muncul—ada juga yang bilang sekadar melengkapi kalimat. Kecanggihan dan performa sebuah model dinilai dari berapa banyak parameter yang dimilikinya. Parameter model adalah jumlah faktor yang dipertimbangkan saat memproses output.
Belajar dari konteks melalui analisis data maksi—bisa teks, audio, atau gambar—model bahasa memprediksi kata/frasa apa yang akan muncul secara berurutan. Lazimnya model bahasa digunakan dalam aplikasi NLP yang menghasilkan keluaran berbasis teks, misal mesin terjemahan.
Penerapan sederhana yang sudah lazim adalah auto complete atau rekomendasi yang diberikan Google saat pengguna mengetikkan lema pencarian. Misal Anda mengetikkan “sambal te..”, Google langsung bisa menyarankan “sambal terasi”, “sambal tempe”, atau “sambal tempoyak”.
Rekomendasi tersebut bisa muncul karena sudah ada data sebelumnya. Besarnya data yang dimiliki Google (penguasa 93 persen pasar mesin pencari di seantero internet) membuatnya memiliki pengetahuan yang luas—yang berasal dari lema pengguna.
Bayangkan ChatGPT yang dilatih dengan 570GB data, atau setara dengan 300 miliar kata. Ini membuatnya memiliki 175 miliar parameter untuk memprediksi. Semakin banyak parameter yang digunakan dalam model, semakin banyak informasi yang dapat dipelajari dan disimpan dalam model.
Dengan 175 miliar parameter, ChatGPT memiliki kapasitas yang sangat besar untuk mempelajari pola bahasa dan menjawab pertanyaan dengan akurasi yang tinggi. Namun, semakin besar jumlah parameter, semakin besar kebutuhan akan sumber daya komputasi.
Ketergantungan pada jumlah data yang dilatihkan membuat mesin ini tak mungkin mengetahui semuanya. Hal-hal yang belum pernah dipelajarinya tidak akan ia mengerti. Misal, data yang dilatihkan untuk mesin yang bisa diakses publik mentok pada data bertarikh 2021.
Bila kita menanyakan peristiwa yang baru terjadi pada 2022 atau 2023, ia akan mengaku tidak tahu. Contohnya soal bencana gempa di Turki dan Suriah pada awal Februari 2023 lalu, atau hasil laga sepakbola di Liga Italia pada musim 2022-2023.
Selain memproduksi kalimat dengan urutan kata terprediksi, ia bisa menampilkan kutipan utuh bila diperlukan. Misal, diminta kutipan Marshall McLuhan terpopuler: “The medium is the message.” – From the book “Understanding Media: The Extensions of Man” (1964), jawabnya.
Tetapi berhati-hatilah, ChatGPT juga bisa membuat kutipan yang seolah dibuat oleh seorang penulis dari buku tertentu, tapi kutipan itu tak pernah ada. Ini sangat mungkin terjadi ketika ia terpengaruh oleh riwayat percakapan sebelumnya.
Sekadar memprediksi urutan kata dapat menjebak mesin “berhalunisasi”—memasangkan kata menjadi kalimat utuh yang tampak masuk akal tapi bukan fakta. Hal ini diakui CTO OpenAI, Mira Murati, dalam wawancaranya bersama majalah Time. Reporter Business Insider pun membuktikannya.
Dengan status ChatGPT saat ini, ia tidak memproduksi pengetahuan baru. Ia bahkan tak mau membuat prediksi masa depan, dengan sopan menolak, menyangkal bahwa sebagai mesin model bahasa ia tidak punya kemampuan meramalkan masa depan.
Chomsky ada benarnya, ChatGPT adalah “plagiator berteknologi tinggi”. Ia bukan profesor yang menelurkan teori-teori baru, memperkaya ilmu pengetahuan. Ia lebih mirip gudang ilmu dengan memori maksi, menyampaikan ulang apa yang dipelajarinya—meski kadang tak akurat.
Ia bisa membantu plagiarisme oleh mahasiswa saat membuat tugas di kampus, kalau mengutip tanpa sumber. Seperti dalam batasan yang dimaksud Oxford, “menyajikan karya atau ide orang lain sebagai milik Anda, dengan atau tanpa persetujuan, tanpa pengakuan penuh.”
Kendati begitu, dari perspektif ahli Hak Kekayaan Intelektual (Intelectual Property), jika materi sumber tidak dikutip secara spesifik, tidak ada persyaratan untuk menyertakan sitasi.” Karena pengetahuan itu ditulis ulang, tidak dikutip langsung secara verbatim.
Penjelasan lain menyatakan ChatGPT dilatih dengan kumpulan data dan materi lainnya dari internet — meskipun kejelasan status sumbernya masih bisa dipertanyakan. Kumpulan data ini bisa saja mengandung materi yang dilindungi UU hak cipta.
Maka saat keluaran ChatGPT mirip atau bahkan identik dengan karya yang sudah ada dapat menimbulkan risiko penggunaan tanpa izin—dapat dianggap melanggar hak cipta. Selain menyasar OpenAI, tindakan hukum juga bisa diarahkan pada pengguna individu.
Dengan segala keterbatasan lazimnya kelahiran teknologi baru, banyak celah lain yang membuat ChatGPT bukan produk sempurna. Ia berpotensi jadi sumber disinformasi saat memberi jawaban tak akurat dan dipercaya penggunanya—yang kemudian menyebarkannya.
Apabila pengguna mempercayai begitu saja apa yang dihasilkan ChatGPT lalu mengklaim luaran itu, ia tak sekadar berpotensi melakukan plagiarisme, tetapi juga menyebarkan disinformasi atau misinformasi.
Jangan coba-coba menggunakan ChatPGT sebagai joki atau bahan contekan joki untuk membuat karya tulis demi koleksi gelar akademis. OpenAI sudah mulai menerapkan algo khusus untuk melacak plagiarisme ChatGPT, sehingga bisa diprediksi apakah tulisan itu buatan robot atau bukan.
Ia juga bukan penulis kreatif yang bisa menghasilkan maha karya, karena kreativitas saat ini bukanlah ranah keahliannya. Mengujinya untuk membuat sajak atau puisi misalnya, tak akan melahirkan karya baru yang bisa menyaingi buah karya WS Rendra.
“Ia seperti seorang sarjana yang dengan percaya diri menjawab pertanyaan meski tidak menghadiri kuliah apa pun. Terlihat seperti orang bodoh tapi percaya diri menulis omong kosong yang sangat meyakinkan,” demikian deskripsi seorang analis kepada The Guardian.
*Photo by Markus Winkler on Unsplash







Menarik ini, tapi model AI ini bisa juga diposisikan sebagai alat bantu ketimbang alat utama.